|
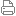
背景Python Python 是一门相当古老的语言了,如今,在数据科学计算、机器学习、以及深度学习领域,Python 越来越受欢迎。 大数据领域,由于 hadoop 和 spark 等,Java 等还是占据着比较核心的位置,但是在 spark 上也可以看到,pyspark 的用户占据很大一部分。 深度学习领域,绝大部分的库(tensorflow、pytorch、mxnet、chainer)都支持 Python 语言,且 Python 语言也是这些库上使用最广泛的语言。 对 MaxCompute 来说,Python 用户也是一股重要力量。 PyData(numpy、scipy、pandas、scikit-learn、matplotlib)Python 在数据科学领域,有非常丰富的包可以选择,下图展示了整个 Python 数据科学技术栈。
可以看到 numpy 作为基础,在其上,有 scipy 面向科学家,pandas 面向数据分析,scikit-learn 则是最著名的机器学习库,matplotlib 专注于可视化。 对 numpy 来说,其中最核心的概念就是 ndarray——多维数组,pandas、scikit-learn 等库都构建于这个数据结构基础之上。 问题虽然 Python 在这些领域越来越流行,PyData 技术栈给数据科学家们提供了多维矩阵、DataFrame 上的分析和计算能力、基于二维矩阵的机器学习算法,但这些库都仅仅受限于单机运算,在大数据时代,数据量一大,这些库的处理能力都显得捉襟见肘。 虽然大数据时代,有各种各样基于 SQL 的计算引擎,但对科学计算领域,这些引擎都不太适合用来进行大规模的多维矩阵的运算操作。而且,相当一部分用户,尤其是数据科学家们,习惯于使用各种成熟的单机库,他们不希望改变自己的使用习惯,去学习一些新的库和语法。 此外,在深度学习领域,ndarray/tensor 也是最基本的数据结构,但它们仅仅限制在深度学习上,也不适合大规模的多维矩阵运算。 基于这些考量,我们开发了 Mars,一个基于 tensor 的统一分布式计算框架,前期我们关注怎么将 tensor 这层做到极致。 我们的工作Mars 的核心用 python 实现,这样做的好处是能利用到现有的 Python 社区的工作,我们能充分利用 numpy、cupy、pandas 等来作为我们小的计算单元,我们能快速稳定构建我们整个系统;其次,Python 本身能轻松和 c/c++ 做继承,我们也不必担心 Python 语言本身的性能问题,我们可以对性能热点模块轻松用 c/cython 重写。 接下来,主要集中介绍 Mars tensor,即多维矩阵计算的部分。 Numpy APINumpy 成功的一个原因,就是其简单易用的 API。Mars tensor 在这块可以直接利用其作为我们的接口。所以在 numpy API 的基础上,用户可以写出灵活的代码,进行数据处理,甚至是实现各种算法。 下面是两段代码,分别是用 numpy 和 Mars tensor 来实现一个功能。 import numpy as npa = np.random.rand(1000, 2000)(a + 1).sum(axis=1)import mars.tensor as mta = mt.random.rand(1000, 2000)(a + 1).sum(axis=1).execute()这里,创建了一个 1000x2000 的随机数矩阵,对其中每个元素加1,并在 axis=1(行)上求和。 目前,Mars 实现了大约 70% 的 Numpy 常用接口。 可以看到,除了 import 做了替换,用户只需要通过调用 execute 来显式触发计算。通过 execute 显式触发计算的好处是,我们能对中间过程做更多的优化,来更高效地执行计算。 不过,静态图的坏处是牺牲了灵活性,增加了 debug 的难度。下个版本,我们会提供 instant/eager mode,来对每一步操作触发计算,这样,用户能更有效地进行 debug,且能利用到 Python 语言来做循环,当然性能也会有所损失。 使用 GPU 计算Mars tensor 也支持使用 GPU 计算。对于某些矩阵创建的接口,我们提供了 gpu=True 的选项,来指定分配到 GPU,后续这个矩阵上的计算将会在 GPU 上进行。 import mars.tensor as mta = mt.random.rand(1000, 2000, gpu=True)(a + 1).sum(axis=1).execute()这里 a 是分配在 GPU 上,因此后续的计算在 GPU 上进行。 稀疏矩阵Mars tensor 支持创建稀疏矩阵,不过目前 Mars tensor 还只支持二维稀疏矩阵。比如,我们可以创建一个稀疏的单位矩阵,通过指定 sparse=True 即可。 import mars.tensor as mta = mt.eye(1000, sparse=True, gpu=True)b = (a + 1).sum(axis=1)这里看到,gpu 和 sparse 选项可以同时指定。 基于 Mars tensor 的上层建筑这部分在 Mars 里尚未实现,这里提下我们希望在 Mars 上构建的各个组件。 DataFrame相信有部分同学也知道 PyODPS DataFrame,这个库是我们之前的一个项目,它能让用户写出类似 pandas 类似的语法,让运算在 ODPS 上进行。但 PyODPS DataFrame 由于 ODPS 本身的限制,并不能完全实现 pandas 的全部功能(如 index 等),而且语法也有不同。 基于 Mars tensor,我们提供 100% 兼容 pandas 语法的 DataFrame。使用 mars DataFrame,不会受限于单个机器的内存。这个是我们下个版本的最主要工作之一。 机器学习scikit-learn 的一些算法的输入就是二维的 numpy ndarray。我们也会在 Mars 上提供分布式的机器学习算法。我们大致有以下三条路: - scikit-learn 有些算法支持 partial_fit,因此,我们直接在每个 worker 上调用 sklearn 的算法。
- 提供基于 Mars 的 joblib 后端。由于 sklearn 使用 joblib 来做并行,因此,我们可以通过实现 joblib 的 backend,来让 scikit-learn 直接跑在 Mars 的分布式环境。但是,这个方法的输入仍然是 numpy ndarray,因此,总的输入数据还是受限于内存。
- 在 Mars tensor 的基础上实现机器学习算法,这个方法需要的工作量是最高的,但是,好处是,这些算法就能利用 Mars tensor 的能力,比如 GPU 计算。以后,我们需要更多的同学来帮我们贡献代码,共建 Mars 生态。
细粒度的函数和类Mars 的核心,其实是一个基于 Actor 的细粒度的调度引擎。因此,实际上,用户可以写一些并行的 Python 函数和类,来进行细粒度的控制。我们可能会提供以下几种接口。 函数 用户能写普通的 Python 函数,通过 mars.remote.spawn 来将函数调度到 Mars 上来分布式运行 import mars.remote as mrdef add(x, y): return x + ydata = [ (1, 2), (3, 4)]for item in data: mr.spawn(add, item[0], item[1])利用 mr.spawn,用户能轻松构建分布式程序。在函数里,用户也可以使用 mr.spawn,这样,用户可以写出非常精细的分布式执行程序。 类 有时候,用户需要一些有状态的类,来进行更新状态等操作,这些类在 Mars 上被称为 RemoteClass。 import mars.remote as mrclass Counter(mr.RemoteClass): def __init__(self): self.value = 0 def inc(self, n=1): self.value += ncounter = mr.spawn(Counter)counter.inc()目前,这些函数和类的部分尚未实现,只是在构想中,所以届时接口可能会做调整。
| 




















 QQ好友和群
QQ好友和群 QQ空间
QQ空间