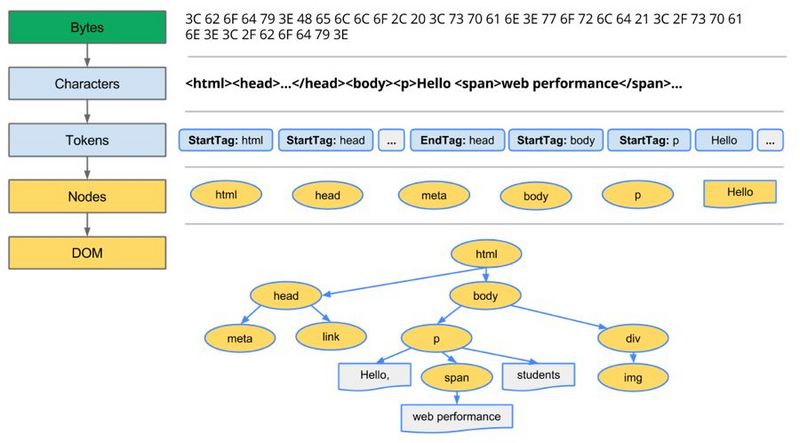
面试中经常会被问到这个问题吧,唉,我最开始被问到的时候也就能大概说一些流程。被问得多了,自己就想去找找这个问题的全面回答,于是乎搜了很多资料和网上的文章,根据那些文章写一个总结。写得不好,或者有意见的 ...
|
面试中经常会被问到这个问题吧,唉,我最开始被问到的时候也就能大概说一些流程。被问得多了,自己就想去找找这个问题的全面回答,于是乎搜了很多资料和网上的文章,根据那些文章写一个总结。 写得不好,或者有意见的直接喷,不用走流程。也欢迎大佬指点 首先这不是小问题,能把里面的过程说清楚真的很麻烦,然后下面我把这些知识点,按流程的形式总结的:
1. 从浏览器接收url到开启网络请求线程多进程的浏览器 浏览器是多进程的,有一个主控进程,以及每一个tab页面都会新开一个进程(某些情况下多个tab会合并进程)。 进程可能包括主控进程,插件进程,GPU,tab页(浏览器内核)等等。
多线程的浏览器内核 每一个tab页面可以看作是浏览器内核进程,然后这个进程是多线程的,它有几大类子线程:
解析URL 输入URL后,会进行解析(URL的本质就是统一资源定位符) URL一般包括几大部分:
网络请求都是单独的线程 每次网络请求时都需要开辟单独的线程进行,譬如如果URL解析到http协议,就会新建一个网络线程去处理资源下载。 因此浏览器会根据解析出得协议,开辟一个网络线程,前往请求资源。 2. 开启网络线程到发出一个完整的http请求DNS查询得到IP 如果输入的是域名,需要进行dns解析成IP,大致流程: 如果浏览器有缓存,直接使用浏览器缓存,否则使用本机缓存,再没有的话就是用host 而且,需要知道dns解析是很耗时的,因此如果解析域名过多,会让首屏加载变得过慢,可以考虑 dns-prefetch优化。 tcp/ip请求 http的本质就是 tcp/ip请求。 三次握手: 四次挥手: tcp/ip的并发限制 浏览器对同一域名下并发的tcp连接是有限制的(2-10个不等)。 get和post的区别 这个东西网上的资料也很多,这儿就大概描述一下在tcp/ip层面的区别,在http层面的区别请读者自行搜索: 具体就是: 然后有读者可能以前了解过OSI的七层:物理层、 数据链路层、 网络层、 传输层、 会话层、 表示层、 应用层 这儿就不班门弄虎了,列一下内容,需要深入理解的读者请自行搜索,计算机网络相关的资料。 1.应用层(dns,http) DNS解析成IP并发送http请求 3. 从服务器接收到请求到对应后台接收到请求后端的操作有点多,我这儿也就不秀自己知识面低下了,哈哈 负载均衡 对于大型的项目,由于并发访问量很大,所以往往一台服务器是吃不消的,所以一般会有若干台服务器组成一个集群,然后配合反向代理实现负载均衡。(据说现在node在微服务的项目方面越来越猛,大并发也不在话下,正在研究node,希望后面能写一个心得) 简单的说:用户发起的请求都指向调度服务器(反向代理服务器,譬如安装了nginx控制负载均衡),然后调度服务器根据实际的调度算法,分配不同的请求给对应集群中的服务器执行,然后调度器等待实际服务器的HTTP响应,并将它反馈给用户。 后台的处理 一般后台都是部署到容器中的,所以一般为: 1.先是容器接受到请求(如tomcat容器) 概括下: 4.后台和前台的http交互前后端交互时,http报文作为信息的载体。 http报文结构 通用头部 其中,Method的话一般分为两批次: HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。 状态码:这是进行请求和回应的关键信息,官方有最全的状态码信息,这儿就列几个常见的: 其他的请读者自行去搜索官方介绍。 对于状态码: 请求/响应头部 请求和响应头部也是分析时常用到的。常用的请求头部(部分): 常用的响应头部: 请求头部和响应头部是有对应关系的:例如 更多的对应关系请读者自行搜索。 请求/响应实体 做http请求时,除了头部,还有消息实体,一般来说,请求实体中会将一些需要的参数都放入进入(用于post请求)。譬如实体中可以放参数的序列化形式( a=1&b=2这种),或者直接放表单对象( FormData对象,上传时可以夹杂参数以及文件),等等。 而一般响应实体中,就是放服务端需要传给客户端的内容。一般现在的接口请求时,实体中就是对于的信息的json格式。 cookie以及优化 cookie是浏览器的一种本地存储方式,一般用来帮助客户端和服务端通信的,常用来进行身份校验,结合服务端的session使用。 常用的场景如下: 用户登陆后,服务端会生成一个session,session中有对于用户的信息(如用户名、密码等),然后会有一个sessionid(相当于是服务端的这个session对应的key),然后服务端在登录页面中写入cookie,值就是:jsessionid=xxx,然后浏览器本地就有这个cookie了,以后访问同域名下的页面时,自动带上cookie,自动检验,在有效时间内无需二次登陆。 一般来说,cookie是不允许存放敏感信息的(千万不要明文存储用户名、密码),因为非常不安全,如果一定要强行存储,首先,一定要在cookie中设置 httponly(这样就无法通过js操作了)。 另外,由于在同域名的资源请求时,浏览器会默认带上本地的cookie,针对这种情况,在某些场景下是需要优化的。 例如以下场景: 当然了,针对这种场景,是有优化方案的(多域名拆分)。具体做法就是: 说到了多域名拆分,这里再提一个问题,那就是: 在移动端,如果请求的域名数过多,会降低请求速度(因为域名整套解析流程是很耗费时间的,而且移动端一般带宽都比不上pc) gzip压缩 首先,明确 gzip是一种压缩格式,需要浏览器支持才有效(不过一般现在浏览器都支持),而且gzip压缩效率很好(高达70%左右)。然后gzip一般是由 apache、 tomcat等web服务器开启。 当然服务器除了gzip外,也还会有其它压缩格式(如deflate,没有gzip高效,且不流行),所以一般只需要在服务器上开启了gzip压缩,然后之后的请求就都是基于gzip压缩格式的,非常方便。 长连接与短连接 首先看 tcp/ip层面的定义:
然后在http层面: 注意: keep-alive不会永远保持,它有一个持续时间,一般在服务器中配置(如apache),另外长连接需要客户端和服务器都支持时才有效。 http 2.0 http2.0不是https,它相当于是http的下一代规范(譬如https的请求可以是http2.0规范的)。然后简述下http2.0与http1.1的显著不同点: 所以,如果http2.0全面应用,很多http1.1中的优化方案就无需用到了(譬如打包成精灵图,静态资源多域名拆分等)。
|





















墨染ART / 2019-01-12

墨染ART / 2019-01-12

李政一 / 2019-01-12

Wotchin / 2019-01-12

Geely / 2019-01-12
24x7小时免费咨询